前言
前期使用**一键脚本安装爬虫网站程序,抓取源默认只有7个**,捕获到可用节点数量范围在30~70个,无法达到理想值3000+,而今天教会大家增加爬虫捕获能力,揭晓捕获3000+免费节点的技术秘密。喜欢的朋友请在页脚点个赞!
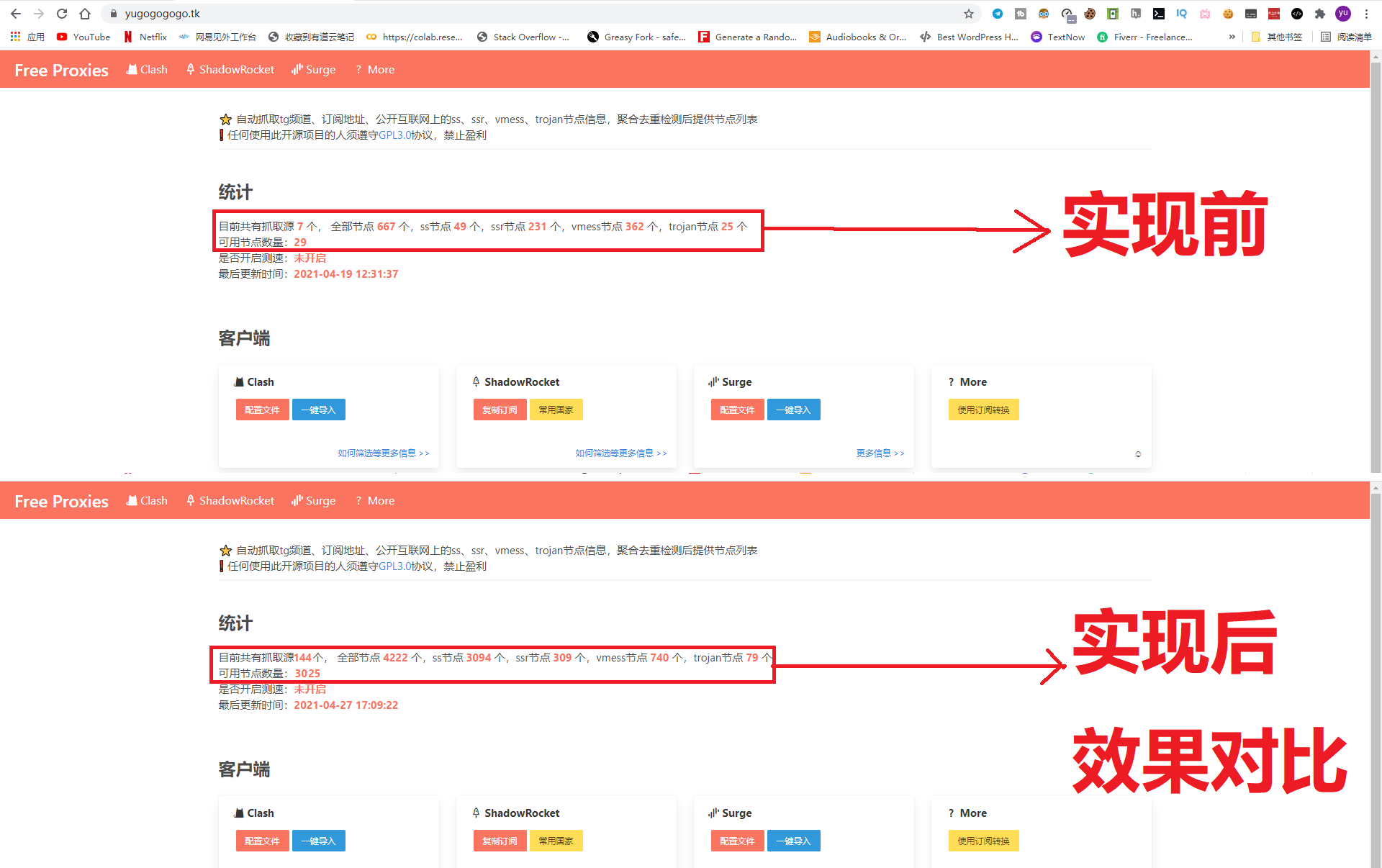
实施前和实施后效果对比:
 阅读这篇文章默认你已经会搭建爬虫程序网站,本篇不再赘述安装,不会的朋友可以到这里充电。 **实现目标:**通过增加抓取源地址,扩宽爬虫捕获更多节点。 爬虫捕获外界免费节点的方式主要通过订阅源给出的地址进行抓取,订阅源地址存放路径在VPS的root根目录下。如:~/source.yaml 抓取能力支持:Telegram频道抓取/订阅地址抓取解析/公开互联网页面模糊抓取;
阅读这篇文章默认你已经会搭建爬虫程序网站,本篇不再赘述安装,不会的朋友可以到这里充电。 **实现目标:**通过增加抓取源地址,扩宽爬虫捕获更多节点。 爬虫捕获外界免费节点的方式主要通过订阅源给出的地址进行抓取,订阅源地址存放路径在VPS的root根目录下。如:~/source.yaml 抓取能力支持:Telegram频道抓取/订阅地址抓取解析/公开互联网页面模糊抓取;
准备条件及打开方法
**准备条件:**已建好的爬虫网站
finalshell打开方法
finalshell下载window地址,macos地址,直接使用finalshell登录远程VPS,找到文件界面依次找到订阅源文件~/source.yaml双击打开编辑,然后保存关闭。
xshell打开方法
订阅源文件打开编辑命令:
vi ./source.yaml
#编辑完成,按“ESC”键,英文:wq 回车即可保存退出。
订阅源设置
为方便更多人读懂爬虫订阅源的写法,实现增加更多订阅源,按照我整理分析科学分类如下:
Telegram写法
复制一份TG范例,用于修改使用。如下图解析TG格式的写法。 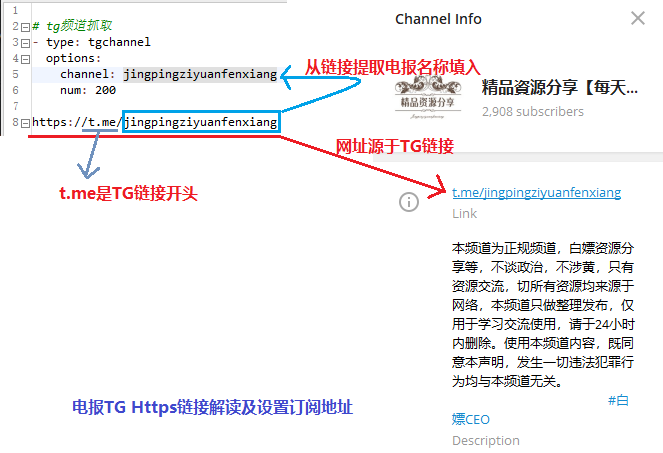 如上图对电报TG https链接解析,最后面的英文单词就是TG的群名称,将名称复制粘贴到新增加的TG订阅源中即可,num:一般设置在100~200之间。 按照上述示例,完成TG订阅源地址增加。 **应用场景:**应用于TG频道群的订阅资源抓取。
如上图对电报TG https链接解析,最后面的英文单词就是TG的群名称,将名称复制粘贴到新增加的TG订阅源中即可,num:一般设置在100~200之间。 按照上述示例,完成TG订阅源地址增加。 **应用场景:**应用于TG频道群的订阅资源抓取。
github写法
目前github据订阅范例分析有两种写法: 1:subscribe;这种订阅类型一般是订阅地址,比如在机场分享的,或者别人公开免费的订阅地址,使用浏览器打开该地址通常显示一堆Base64编码的,那么type类型就选择:subscribe **应用场景:**如果知道这样信息网址,订阅类型选填”subscribe“
以下是应用举例:
# type选择subscribe,url填入网址
- type: subscribe
options:
url: https://raw.githubusercontent.com/ssrsub/ssr/master/v2ray
下图为:https://raw.githubusercontent.com/ssrsub/ssr/master/v2ray浏览器打开效果。 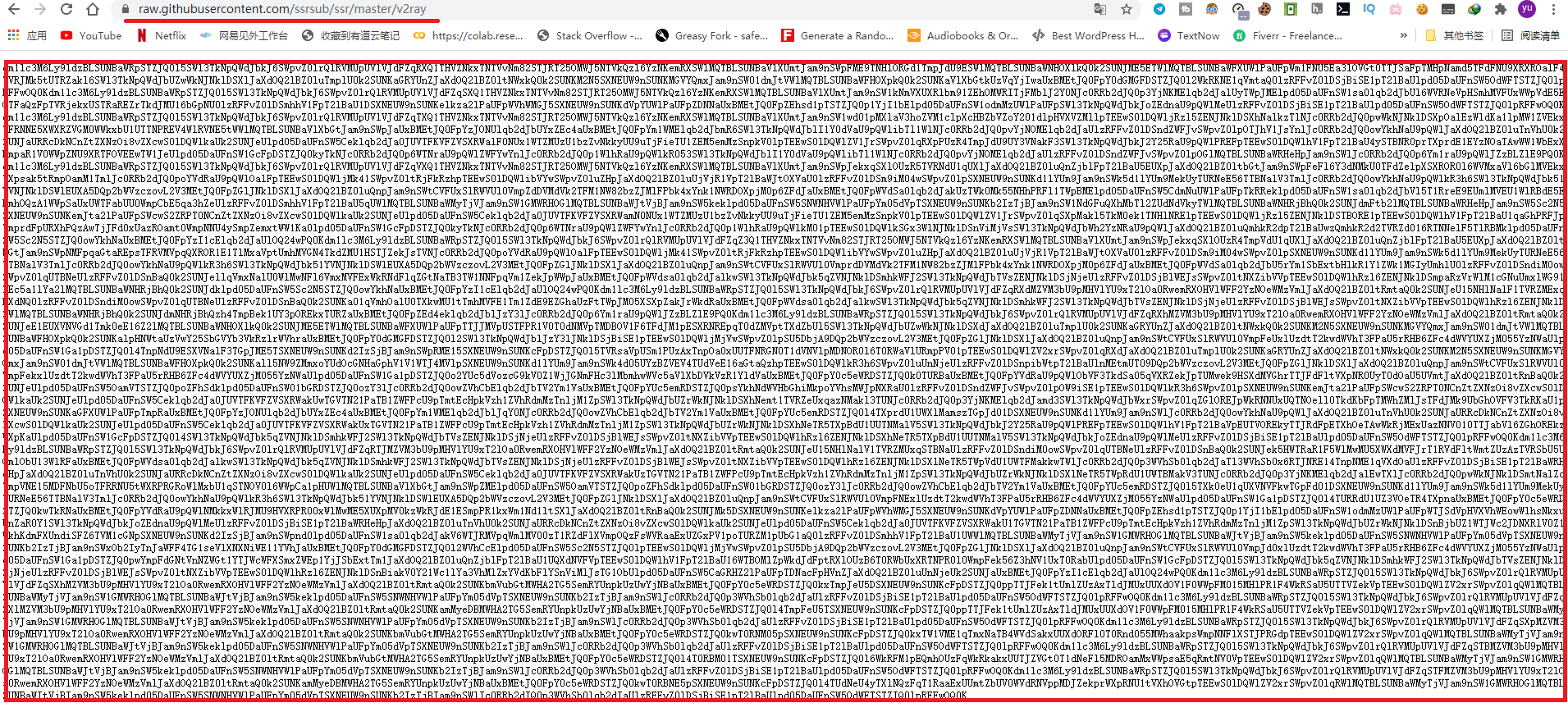 2:
2:webfuzzsub:这种类型,存放的内容不是Base64编码信息,通常会是subscribe的集合,比如一堆订阅地址(如:clash,config,json,txt,sub后缀文件)等。 **应用场景:**如果知道这样集合信息网址,订阅类型选填”webfuzzsub“ 以下是应用举例:
# 模糊抓取订阅链接
- type: webfuzzsub
options:
url: https://raw.githubusercontent.com/du5/free/master/sub.list
下图为:https://raw.githubusercontent.com/du5/free/master/sub.list浏览器打开效果。 
**通过github网址解读发现:**如”https://raw.githubusercontent.com/du5/free/master/sub.list“,”raw.githubusercontent.com“是github下载网址开头,”du5“通常为”用户名或机构名“,后面组成成份就是项目或项目分支,有了解读经验,我们甚至可以在github找到”du5“用户该项目下面的更多订阅信息,尤其是时效性比较强的文件。
翻墙党论坛写法
翻墙党论坛的抓取源设置简单,直接找到可用节点信息网页,把下面type类型设为:web-fanqiangdang,把静态网页网址粘贴进去即可。如下配置:
# 翻墙党论坛抓取
- type: web-fanqiangdang
options:
url: https://fanqiangdang.com/forum-48-1.html
网页模糊抓取写法
这种订阅类型”webfuzz“,和”webfuzzsub“类似,也是订阅地址的合集,可以二选一。作用范围:模糊抓取网页所有订阅地址,示例可以自行打开url查看,配置如下:
# 网页模糊抓取
- type: webfuzz
options:
url: https://merlinblog.xyz/wiki/freess.html
clash格式写法
只要知晓yaml或yml后缀文件公开的网址,就可以把”type“类型换成clash,它只读取clash专用配置,靶式抓取更精准。配置示例如下:
# clash格式订阅链接
- type: clash
options:
url: https://raw.githubusercontent.com/du5/free/master/file/0909/Clash.yaml
该网址打开效果如下图: 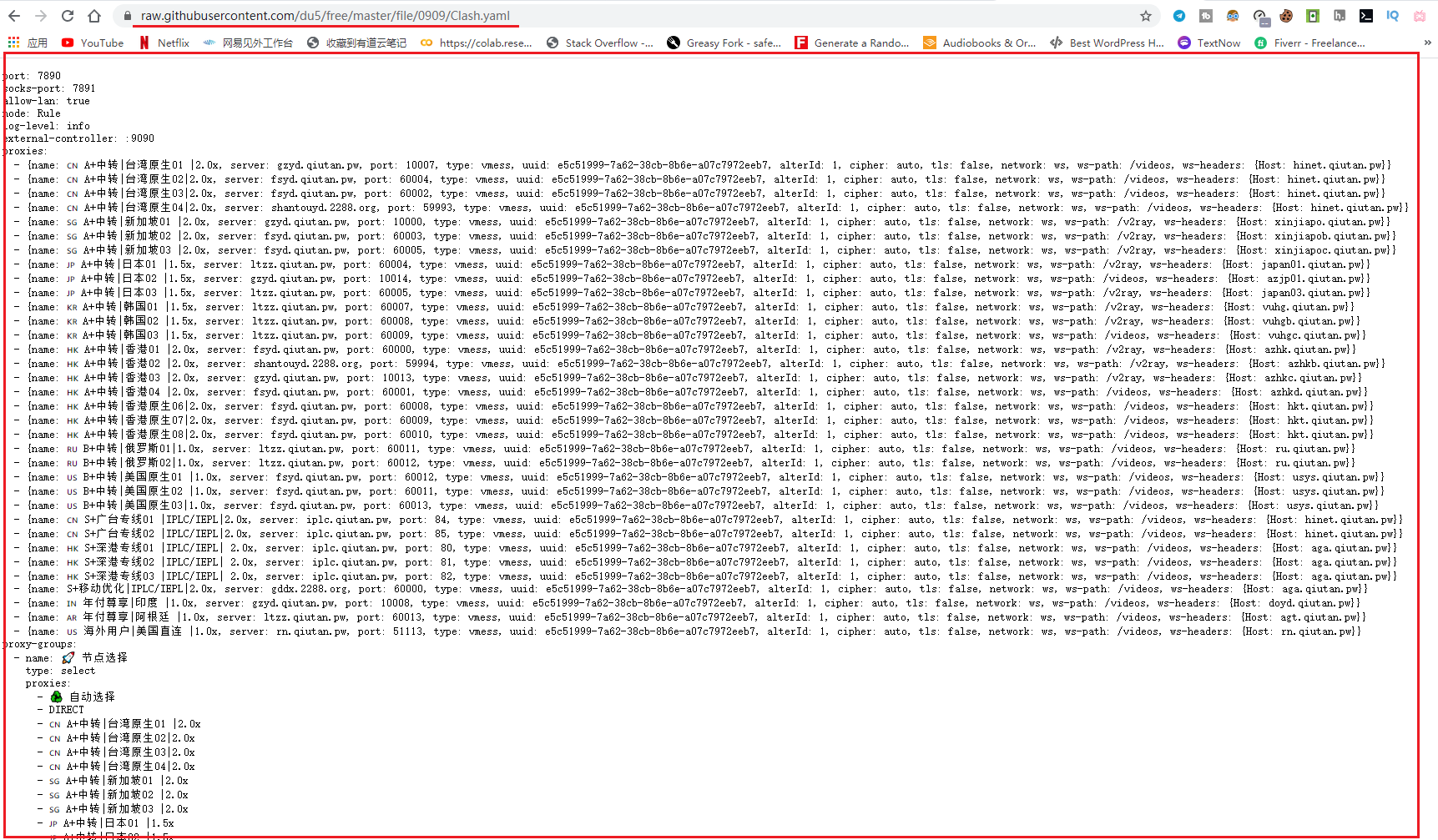
启动生效
最后记得保存修改好的source.yaml文件,并且使用以下命令停止当前爬虫程序(若你刚开始,可以忽略第1~4条命令,直接执行第6条命令)
#第1-4完成ID查看并杀掉该进程
ps -ef grep proxy
root 4763 4650 0 16:58 pts/0 00:00:00 grep –color=auto proxy
root 19510 1 0 4月25 ? 00:04:10 ./proxypool -c config.yaml
kill 19510
nohup ./proxypool -c config.yaml >/dev/null 2>/dev/null &
[1] 11215
上述配置解释,第2,3行显示当前爬虫运行进程ID,第7行显示后台运行爬虫进程号,
后记
以上就是订阅源地址各写法解析,大家可以根据规则完成订阅资源增加,建立爬虫网站功能优点好处多多如下: 支持ss、ssr、vmess、trojan多种类型 Telegram频道抓取 订阅地址抓取解析 公开互联网页面模糊抓取 定时抓取自动更新 通过配置文件设置抓取源 自动检测节点可用性 提供clash、surge配置文件 如看不明白或对相关视频教程感兴趣,欢迎点击此处观看
转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 lanhebe@gmail.com

